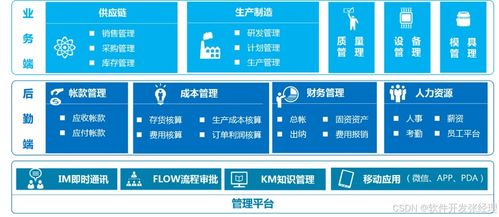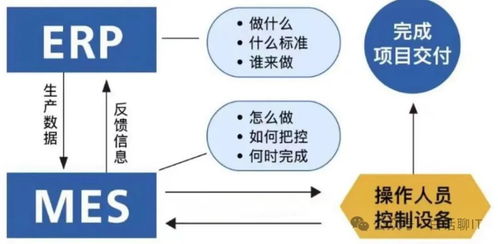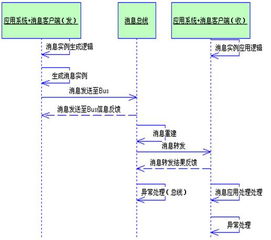
在信息系統集成服務中,消息中心作為核心通信樞紐,其穩定運行至關重要。實踐中常因Web服務器問題引發消息中心各組件間協作失效,本文將系統分析其成因并提出針對性解決方案。
一、問題現象與影響分析
消息中心通常由消息隊列、推送服務、用戶接口等多個組件構成。當Web服務器出現故障時,首先表現為:1)消息投遞延遲或丟失;2)推送服務無法響應客戶端請求;3)管理界面無法加載或操作超時。這類問題直接影響業務連續性,尤其在電商、金融等實時性要求高的場景中,可能導致交易失敗、用戶流失等嚴重后果。
二、根本原因探究
通過日志分析和壓力測試,我們發現主要成因包括:
- Web服務器資源瓶頸:CPU、內存或網絡帶寬不足,無法處理高并發請求,導致組件間心跳檢測超時。
- 配置錯誤:如反向代理規則不當、SSL證書失效,阻斷組件間HTTPS通信。
- 依賴服務異常:數據庫連接池耗盡或緩存服務宕機,間接引發Web服務線程阻塞。
- 代碼缺陷:未合理處理異常重試機制,單點故障迅速擴散至整個消息鏈路。
三、系統化解決方案
- 基礎設施優化:
- 采用負載均衡集群部署Web服務器,通過Nginx實現流量分發與故障轉移。
- 實施彈性擴縮容策略,基于監控指標(如QPS、響應時間)動態調整資源。
- 架構設計改進:
- 引入熔斷器模式(如Hystrix),在組件通信失敗時快速降級,避免雪崩效應。
- 部署異步消息緩沖層,通過RabbitMQ或Kafka解耦組件依賴,確保消息持久化。
- 運維監控增強:
- 建立全鏈路追蹤體系,使用SkyWalking或Zipkin定位故障邊界。
- 配置自動化告警規則,對服務器狀態、API成功率等指標進行實時閾值檢測。
- 容災與測試保障:
- 定期開展混沌工程演練,模擬服務器宕機場景驗證系統自愈能力。
- 在集成測試中覆蓋網絡分區、超時異常等邊界用例,完善故障處理邏輯。
四、實踐案例與效果
某金融機構在實施上述方案后,消息中心可用性從97.3%提升至99.95%,故障平均修復時間(MTTR)由4小時縮短至15分鐘。關鍵改進包括:將單體Web服務拆分為微服務架構,采用多可用區部署;通過APM工具發現并修復了數據庫連接泄漏問題;建立灰度發布機制避免配置變更引發全局故障。
Web服務器穩定性是消息中心可靠運行的基石。通過‘預防-監測-恢復’三位一體的治理策略,結合持續優化的技術架構,可顯著提升信息系統集成服務的魯棒性與業務連續性。未來,建議進一步探索服務網格(如Istio)在組件通信治理中的應用,構建更智能的故障預測與自愈體系。